Why It Exists
Ordinary FPGA multiplication can become the wrong abstraction. A standard Verilog * may infer hardware with slow clock semantics, difficult timing closure, and pressure on DSP blocks. For some compute graphs, the problem is not multiplying once. The problem is composing many multipliers and adders at high clock rate without turning the design into wide buses, placement trouble, and memory traffic.
This multiplier takes the opposite route. It keeps arithmetic in a narrow, regular, bit-serial stream. Every edge carries one bit per clock, every word advances on the same cadence, and the pipeline does not need a bubble between consecutive operands.
Streaming Behavior
The input streams are LSB-first. The output stream is also LSB-first. In the rendered 8-bit circuit, the fixed pipeline latency is 3 clocks, matching the depth of the balanced serial reduction tree. Once that latency is accounted for, output bits continue one per clock.
"Bubbles-free" means there is no idle drain period between words. The next operand word begins immediately after the previous operand word in the same stream cadence. The output side behaves the same way: after the fixed latency, result bits keep coming on every clock.
There is no reset/start framing between words and no ready/valid backpressure in this artifact. The stream phase begins from power-on phase, and the surrounding circuit must know which clock corresponds to bit 0 of each word.
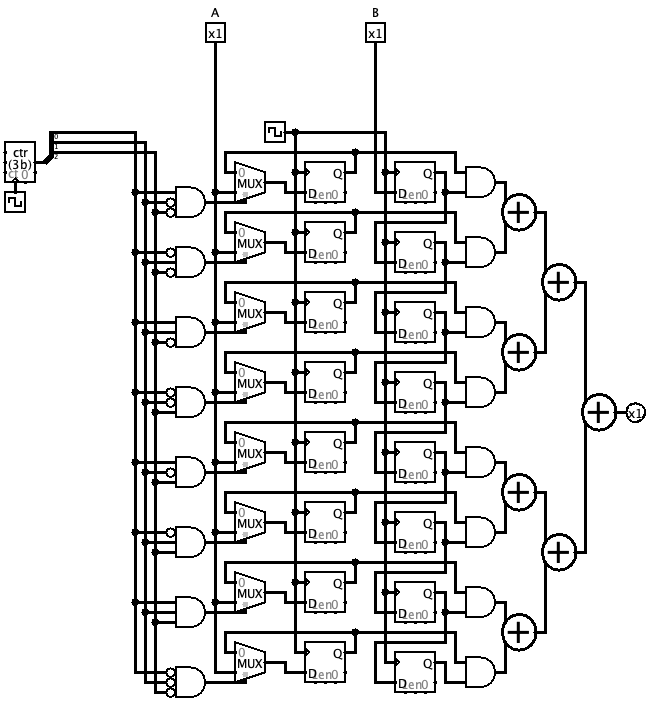
Schematic Anatomy
The Logisim file contains harness and helper circuits, but the important pieces are compact:
varserializes an 8-bit value into a one-bit stream.addis the clocked serial adder and carries the serial carry state.mulgenerates partial-product lanes and reduces them through a balanced tree of serial adders.dbg,main, andmain2are inspection and harness support.
Partial products are not stored as a wide parallel matrix. They exist as delayed and gated bit streams feeding the serial reduction tree. Carry propagation is local to the serial adders rather than a wide carry chain across a parallel product bus.
Scaling
The design scales linearly in resources with the number of input bits. Wider versions add repeated lanes and reduction structure instead of a wide parallel multiplier block. The balanced serial reduction tree adds one clock of extra latency each time operand width doubles.
The useful output width is an application decision. In fixed-width DSP, SDR, AI, and graphics arithmetic, the designer usually knows which product bits matter. Keeping only the useful stream width is part of the architecture, not a failure to compute a decorative full-width product. Signed arithmetic can be added with a cheap parallel sign stream.
Tradeoff
The tradeoff is not simply "serial is slower." The architecture gives up wide immediate products in exchange for a uniform streaming schedule, narrow local links, and graph-style composition. That can reduce routing pressure and make large arithmetic graphs easier to reason about, place, and clock.
Hard DSP blocks and inferred * multipliers remain useful, but they also bring placement and clocking constraints. This design explores the opposite direction: keep multiplication in the same bit-stream rhythm as the rest of the compute graph and aim for fabric-friendly Fmax.
Artifacts
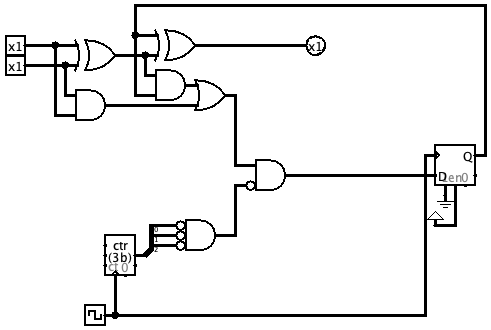 Serial adder image
Serial adder image
The next engineering step is a Verilog port, followed by LUT count, achievable Fmax, timing reports, waveform captures, and comparison against inferred * and DSP-backed multipliers on the same target.